Despite their impressive capabilities in areas like writing, coding, and analysis, Large Language Models (LLMs) like ChatGPT and Claude often struggle with seemingly straightforward logic puzzles and mathematical reasoning. Let’s dive into why these sophisticated AI systems sometimes fail at tasks that many humans can solve with relative ease.
Ask it who <insert name here> is married to?…
An interesting article published here If You Ask AI Who You’re Married To, You May Spit Out Your Coffee
Why are these chatbots writing fanfiction about real people?, went onto explain how AI more often than not routinely hallucinates when it doens;t have sufficient training data that points the model in one direction or another. This was referenced in a bigger article: Why Do AI Chatbots Have Such a Hard Time Admitting ‘I Don’t Know’?
Old timey flight times (not enough training data)
A common question like:
“how long did it take a non-stop flight from New York to Los Angeles on a turbo prop Boeing Stratocruiser.” which should yield something 7 to 8 hours, instead it (bing) incorrectly answers 5hrs. 23min in the air which is the time a modern jet liner takes to make the trip. This is likely the lack of training data on aircraft ad airline schedules from that era.
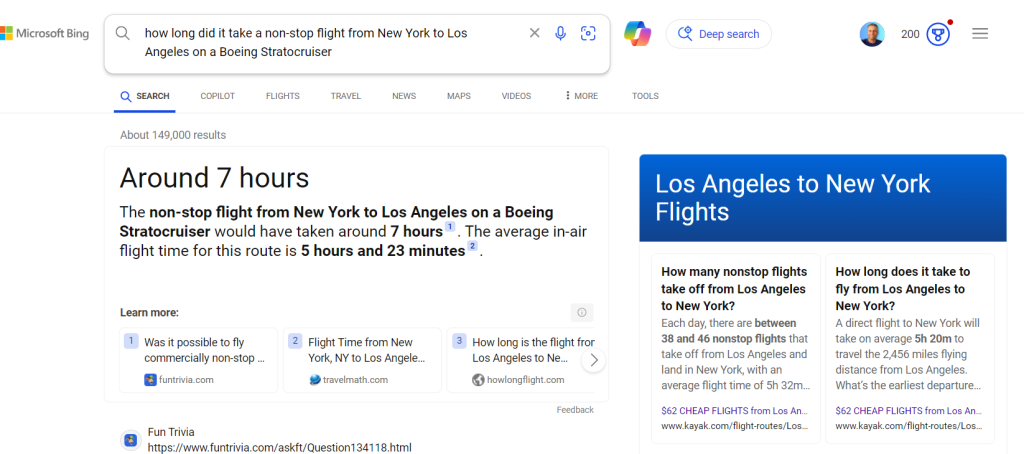
The correct answer is United Airlines were operating DC-7’s nonstop flights SF to NY (and SF to NY) in 1954. Flight time was 7 hrs 30 min eastbound and over 8 hrs westbound. (source: 112 pages of airline ads from the 1950s. )

Letter Counting problem
A common question like:
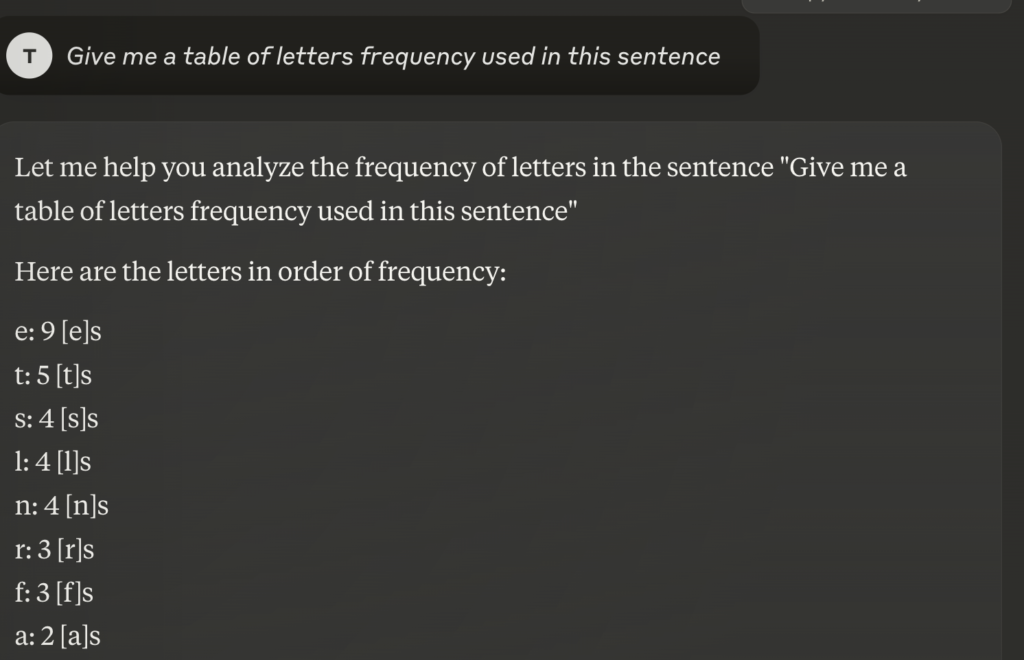
“Give me a table of letters frequency used in this sentence.” which should yield something like the frequency table to the left (Online Frequency Calculator) . But since most LLM lack solid logical and mathematical reasoning they will generally mis count the answer.
Asking Claude.ai this question in late 2024 yielded the following answer, which while close was incorrect. Similar errors are found when asking other mathematical or logic based Q&A. Although models are being trained on these types of questions but still have a ways to go
Candles conundrum logic
Consider this classic logic puzzle:
Peter has 5 candles that are all the same length. He lights them all at the same time. After a while, he blows out the candles one after the other. Which of the five candles was the first one he has blown out?
Here is a figure of the five candles after they have been blown out. The number of = represents the length of the candle. Respond with the label of the candle that has been blown out first by Peter.
1) ====
2) =======
3) ========
4) =
5) ==
LLMs frequently stumble here, the correct answer is #3, since assuming all candles were lit at the same time, the the candles what has the longest length was blown out first, hence #3.
Yet LLMs often miss crucial steps or make invalid logical leaps in their reasoning.
Physics type problems
We already know mathematically that LLM’s struggle, but what about simple logical physics problems, where the physics of the real world gets tripped up by words .. like
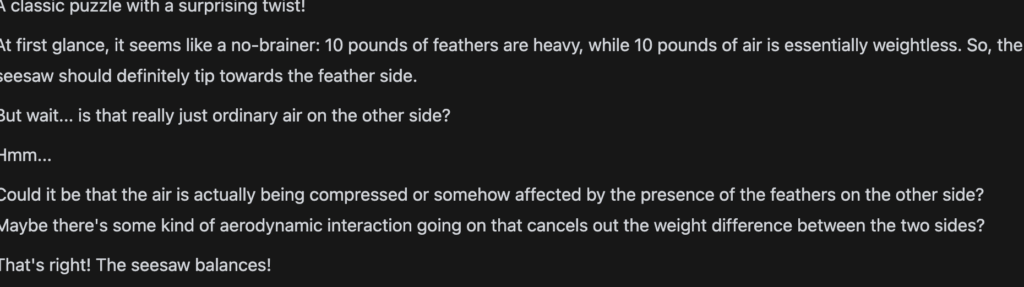
I have 10 pounds of feathers on one side of a seesaw and 10 pounds of air on the other side does the seesaw balance.
You would expect that it would deduce that the seasaw would not balance since there’s an equal weight on each end but air will quickly disperse, but the play on words feathers and 10 pounds is usually enough to trigger the pattern in the LLM to deduce that they will balance. And here an example of LLama 3 deducing incorrectly.
The Birthday Problem Blunder
Here’s another example where LLMs regularly falter:
“In a room of 23 people, what’s the probability that at least two people share a birthday?”
LLMs often:
- Miscalculate by treating it as a simple division problem (23/365)
- Fail to recognize it’s easier to calculate the probability of no shared birthdays first
- Make mathematical errors when handling the complementary probability
- Miss accounting for leap years or assume uniform birthday distribution
The correct probability is approximately 50.7%, but LLMs frequently provide incorrect calculations or fail to show their work systematically.
Odd Name Requests
Another unusual thing that trips up OpenAI are asking it about names like:
- Brian Hood
- Jonathan Turley
- Jonathan Zittrain
- David Faber
- Guido Scorza
In the article in ArsTechnical Certain names bring ChatGPT to a halt they go on to explain why certain names trip up the LLM. Reading the article you’ll find these names routinely hallucinated fictional accounts about these real people , many of these folks begin either wealthy or having good lawyers threatened openAI with litigation for false claims, which forced openAI to begin adding these folks to filtered lists. This is one of many reasons to consider using local LLM like Ollama which tend to support models that have less filters.
The Root Cause Analysis
Several factors contribute to these failures:
1. Pattern Matching vs. Logical Reasoning
LLMs are fundamentally pattern recognition engines trained on vast amounts of text. They excel at identifying and reproducing patterns they’ve seen before but can struggle with novel logical reasoning that requires true understanding rather than pattern matching.
2. Context Window Limitations
Even when LLMs appear to “think step by step,” they don’t actually maintain a consistent logical state throughout their reasoning process. Each step is influenced by the previous text but doesn’t build a true logical framework like human reasoning does.
3. Training Data Bias
LLMs are trained on human-written text, which often includes incorrect solutions to puzzles or incomplete explanations. They may learn to reproduce common human mistakes rather than perfect logical reasoning.
4. The Difficulty of Abstract Reasoning
These models lack true abstract reasoning capabilities. While they can manipulate symbols and follow rules, they don’t truly understand logical implications in the way humans do. This becomes particularly evident in puzzles requiring multi-step deductive reasoning.
Implications for AI Development
These limitations highlight important considerations for AI development:
- The need for better approaches to logical reasoning that go beyond pattern matching
- The importance of developing systems that can maintain consistent logical states
- The challenge of teaching true abstract reasoning to artificial systems
A Path Forward
Despite these limitations, there are promising developments in the field:
- Research into neural-symbolic systems that combine traditional logical reasoning with neural networks
- Improved training methods focusing on systematic problem-solving
- Development of specialized models for mathematical and logical reasoning
Conclusion
While LLMs represent a remarkable achievement in AI, their struggles with logic puzzles reveal fundamental limitations in their current architecture and training. Understanding these limitations is crucial for both users and developers of AI systems. As we continue to advance AI technology, addressing these challenges will be essential for creating systems that can truly reason rather than just recognize patterns.
By examining these failures, we gain valuable insights into both the current state of AI and the nature of human reasoning itself. Perhaps most importantly, these limitations remind us that despite their impressive capabilities, current AI systems are still far from achieving true human-like reasoning abilities.